时间:2026-05-10 编辑:news
minimax数字人的生成是一个复杂且涉及多领域技术融合的过程。
首先,数据采集是基础。需要收集大量的文本、图像、音频等多模态数据。这些数据来源广泛,包括互联网公开资源、专业领域数据库以及定制的采集内容。文本数据用于训练数字人的语言理解和生成能力,图像数据助力其视觉感知与表达,音频数据则完善语音交互等功能。
接着是模型构建。采用先进的深度学习算法,构建包含自然语言处理、计算机视觉、语音识别等多模块的综合模型。通过大量数据的训练,让模型学习到语言的模式、图像的特征以及语音的规律,从而能够准确理解输入信息并做出合理回应。
在生成数字人的外观形象时,运用计算机图形学技术。对人物的面部特征、肢体动作等进行精细建模和动画绑定。通过高精度的三维建模工具,打造出具有逼真外貌和流畅动作的数字人形象,使其在视觉上能够给人以真实的感受。
语言交互方面,基于模型训练的成果,赋予数字人强大的语言理解与生成能力。它能够准确识别用户的语音指令或文本输入,依据上下文进行智能分析,并以自然流畅的语言进行回应。通过不断优化语言模型,提升其回答的准确性、逻辑性和趣味性。
同时,持续的优化与改进贯穿整个生成过程。根据实际应用场景中的反馈,对数字人的表现进行评估和调整。不断更新数据、优化模型参数,以适应不同用户的需求和多样化的场景,从而逐步生成更加智能、高效、逼真的minimax数字人,为用户带来更优质的交互体验,在众多领域发挥重要作用。
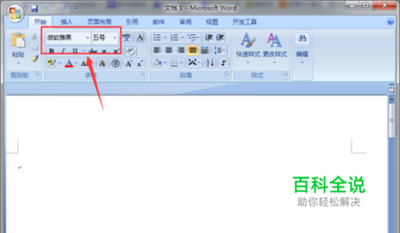
在日常使用office办公软件时,设置默认字体可以让文档、表格和演示文稿具有统一的风格,提升整体专业性。下面就来详细介绍word、excel和ppt默认字体的设置方法。word默认字体设置打开word文档,点击“文件”选项卡,选择“选项”。在弹出的“word选










